# 저장 프로시저(Stored PROCEDURE)
일련의 쿼리를 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합
데이터베이스에서 SQL을 통해 작업을 하다 보면, 하나의 쿼리문으로 원하는 결과를 얻을 수 없을 때가 생긴다. 원하는 결과물을 얻기 위해 사용할 여러줄의 쿼리문을 한 번의 요청으로 실행하면 좋지 않을까? 또한, 인자 값만 상황에 따라 바뀌고 동일한 로직의 복잡한 쿼리문을 필요할 때마다 작성한다면 비효율적이지 않을까?
이럴 때 사용할 수 있는 것이 바로 프로시저다.
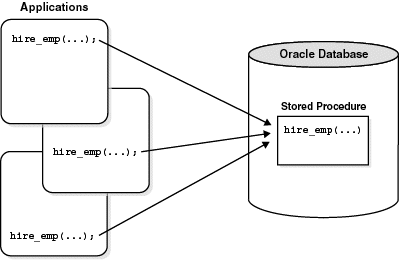
프로시저를 만들어두면, 애플리케이션에서 여러 상황에 따라 해당 쿼리문이 필요할 때 인자 값만 전달하여 쉽게 원하는 결과물을 받아낼 수 있다.
# 프로시저 생성 및 호출
CREATE OR REPLACE PROCEDURE 프로시저명(변수명1 IN 데이터타입, 변수명2 OUT 데이터타입) -- 인자 값은 필수 아님
IS
[
변수명1 데이터타입;
변수명2 데이터타입;
..
]
BEGIN
필요한 기능; -- 인자값 활용 가능
END;
EXEC 프로시저명; -- 호출
# 예시1 (IN)
CREATE OR REPLACE PROCEDURE test( name IN VARCHAR2 )
IS
msg VARCHAR2(5) := '내 이름은';
BEGIN
dbms_output.put_line(msg||' '||name);
END;
EXEC test('규글');
내 이름은 규글
# 예시2 (OUT)
CREATE OR REPLACE PROCEDURE test( name OUT VARCHAR2 )
IS
BEGIN
name := 'Gyoogle'
END;
DECLARE
out_name VARCHAR2(100);
BEGIN
test(out_name);
dbms_output.put_line('내 이름은 '||out_name);
END;
내 이름은 Gyoogle
# 프로시저 장점
# 최적화 & 캐시
프로시저의 최초 실행 시 최적화 상태로 컴파일이 되며, 그 이후 프로시저 캐시에 저장된다.
만약 해당 프로세스가 여러번 사용될 때, 다시 컴파일 작업을 거치지 않고 캐시에서 가져오게 된다.
# 유지 보수
작업이 변경될 때, 다른 작업은 건드리지 않고 프로시저 내부에서 수정만 하면 된다. (But, 장점이 단점이 될 수도 있는 부분이기도.. )
# 트래픽 감소
클라이언트가 직접 SQL문을 작성하지 않고, 프로시저명에 매개변수만 담아 전달하면 된다. 즉, SQL문이 서버에 이미 저장되어 있기 때문에 클라이언트와 서버 간 네트워크 상 트래픽이 감소된다.
# 보안
프로시저 내에서 참조 중인 테이블의 접근을 막을 수 있다.
# 프로시저 단점
# 호환성
구문 규칙이 SQL / PSM 표준과의 호환성이 낮기 때문에 코드 자산으로의 재사용성이 나쁘다.
# 성능
문자 또는 숫자 연산에서 프로그래밍 언어인 C나 Java보다 성능이 느리다.
# 디버깅
에러가 발생했을 때, 어디서 잘못됐는지 디버깅하는 것이 힘들 수 있다.